
Threading¶
The smallest unit of executable program is known as a thread.
We can adjust the number of MPI processes and threads, but the product of the two should ideally be the total number of cores. For example, with 8 cores, we can have 2 processes and 4 threads per process or 1 process with 8 threads. In NEST, we recommend only having one thread per core.
We can control the number and placement of threads with programs that implement standards such as OpenMP.
For a detailed investigation, we recommend reading Kurth et al. 2022 [1].
Pinning threads¶
Pinning threads allows you to control the distribution of threads across available cores on your system, and is particularly useful in high performance computing (HPC) systems.
Allowing threads to move can be beneficial in some cases. But when threads move, the data that is to be processed needs to move too. With NEST, each thread gets allocated a specific set of data objects to work with during simulation (due to the round robin distribution). This means that when a thread moves, it cannot perform any computation until its specific data gets to the right place. This is called cache misses. For this reason, pinning threads typically decreases run time. See our overview handling threads with virtual processes.
There are different types of pinning schemes, and the optimal scheme will depend on your script. Here we show two different example schemes.
Sequential pinning scheme¶
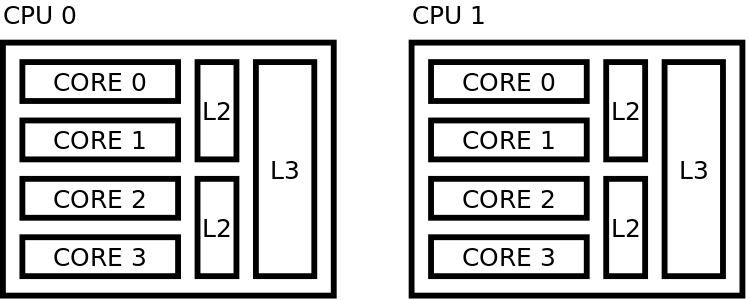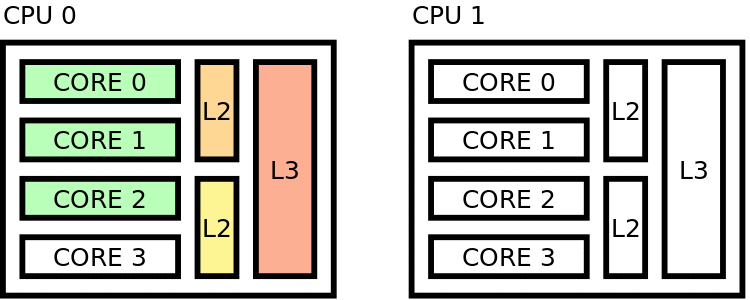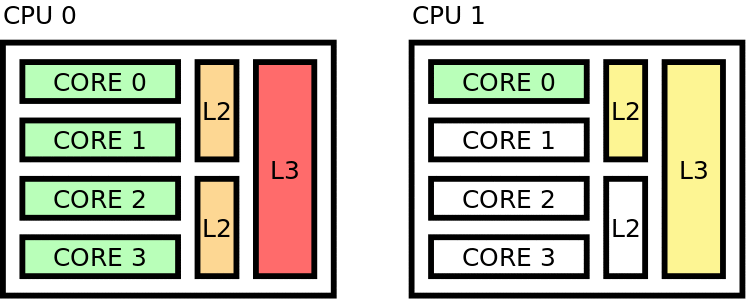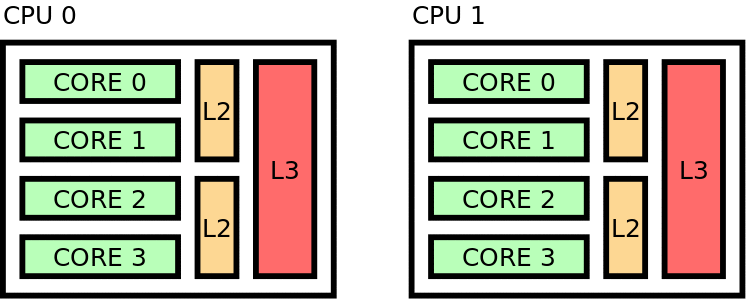
Figure 39 Sequential placing¶
In this scheme, the cores of 1 CPU are filled before going to next
Setting to use for this case: export OMP_PROC_BIND = close
Distant pinning scheme¶
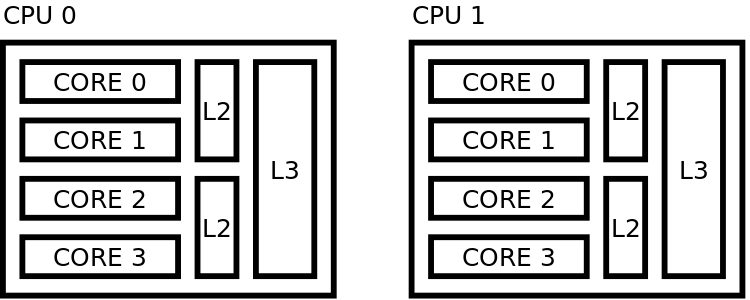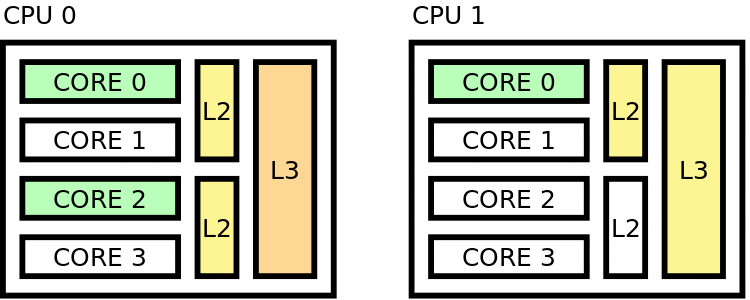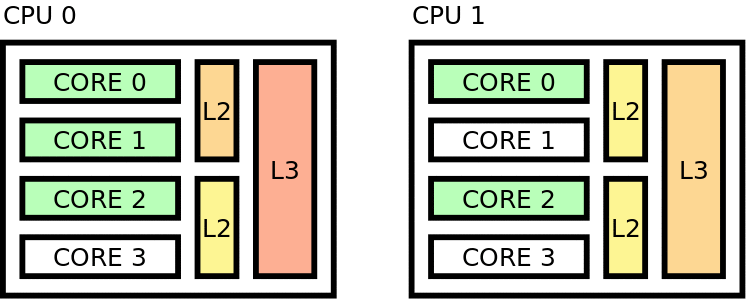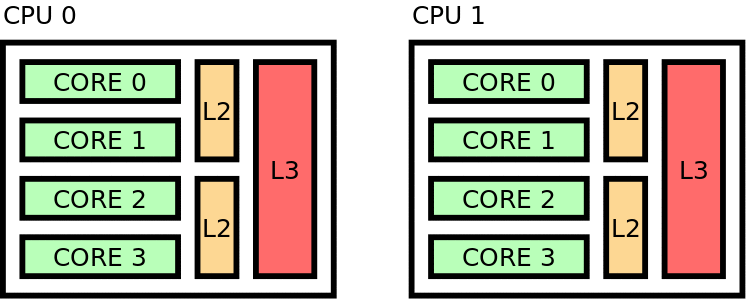
Figure 40 Distant placing¶
Maximizes distance between threads in hardware
Setting to use for this case: export OMP_PROC_BIND = spread
Table of OpenMP settings¶
Setting |
Description |
|---|---|
|
variable telling OpenMP how many threads are used on a MPI process |
|
no movement of threads between OpenMP threads and OpenMP places |
|
no movement of threads between OpenMP threads and OpenMP places and OpenMP places are ‘close’ in a hardware sense |
|
each OpenMP place corresponds to a hardware thread/core |
|
OpenMP places are a, a+b, a+2c, … a+nc=b (numbering usually relates to cores/hardware threads) |
|
display OpenMP variables |
Note
Using `python` on HPC systems might lead to inconsistencies in multi-threading libraries resulting in a degredation of performance.
For instance, depending on the installation `numpy` uses the multi-threading library provided by the MKL.
To resolve this one needs to set `export MKL_THREADING_LAYER=GNU` in order to pass the OpenMP settings correctly.
See also
For general details on pinning in HPC systems see the HPC wiki article.